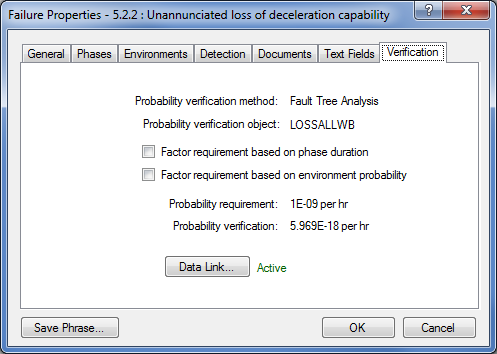
Howdy, folks. Jeremy mentioned it was coming a few months back, but now it's finally here! The Isograph Network Availability Prediction (NAP) 2.0 official release happened under our noses a few weeks ago. I wanted to talk about this product and the new updates to it.
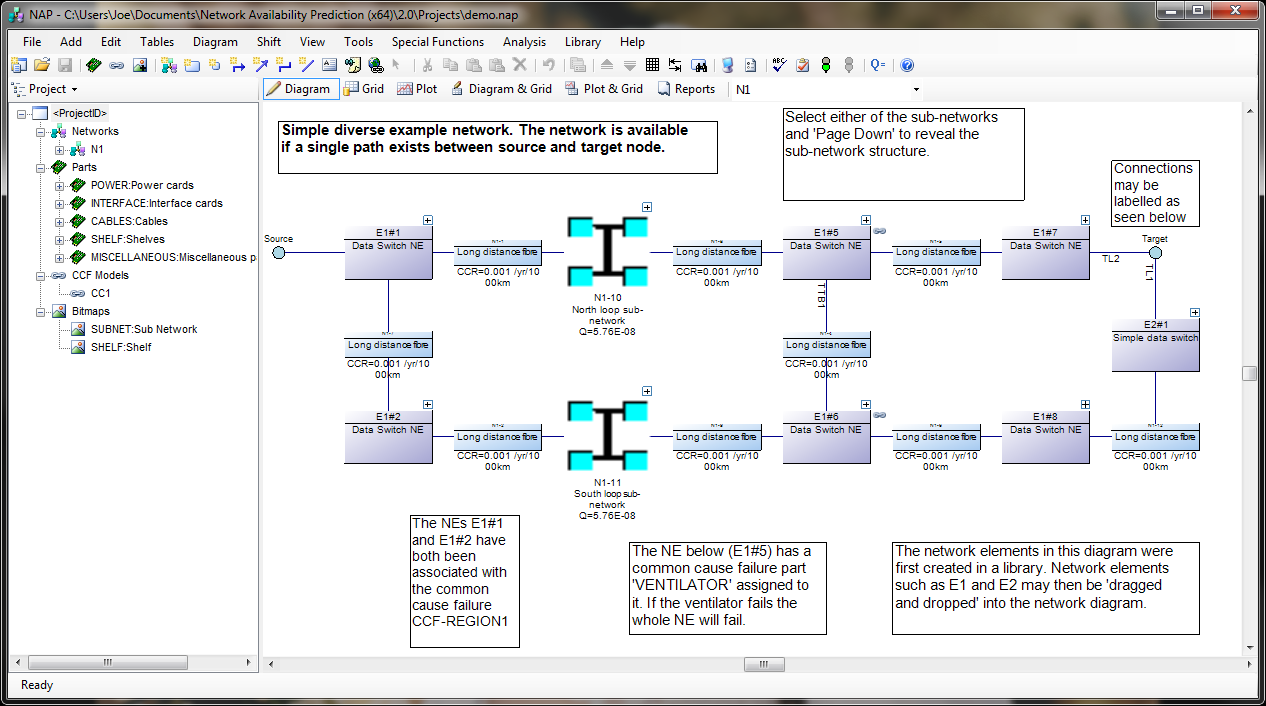
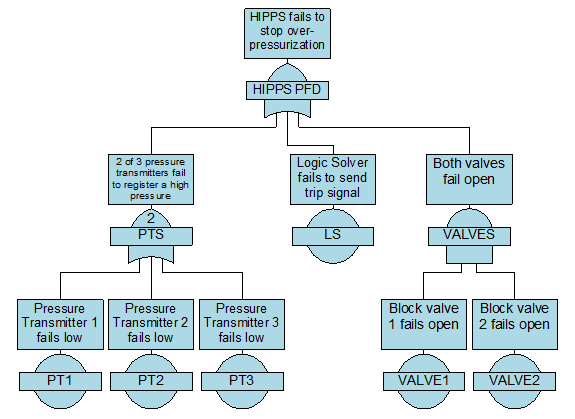
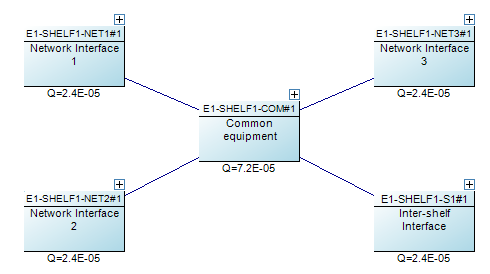
NAP is one of our lesser-used products. It's not as common as Fault Tree or RCMCost, so I'll introduce you to it first, in case you haven't heard of it. NAP is an extension of the analytical RBD methodologies found in Reliability Workbench. It's based on an RBD, but the RBD features have been expanded a great deal in order to allow modeling of telecommunications networks. These Network Block Diagrams (NBDs) differ from RBDs in that they allow for two-way connections and sockets.
- In traditional RBDs, a connection only allows for a one-way logical flow, and each block diagram must have a single input and output. This makes the block diagram evaluation simple, but makes it difficult to evaluate complex communications networks. NBDs are an expansion of that. The two-way flow along connections allows more complex systems modeling, and sockets allow each block diagram to have multiples inputs and outputs. When evaluating, NAP will find all valid paths through the system, from the top level source to target nodes. The network diagram must still have a single source-target pair at the highest level; this is how availability is measured. Once it's identified all paths, then it will determine the cut sets that would block all possible paths, much like an RBD.
NAP also features a Parts library. Failure data is entered for these parts. In addition to standard failure rate or MTTF, which are quantities allowed in RBDs, NAP also has a Cable part type, which measures failures in cuts per distance per time. This makes it easier to model failures associated with the cable connection between two network elements. The Parts library also makes it easy to do "what if" analysis, by swapping similar components in and out of the block diagram, to evaluate how using a different BOM could impact the network availability.
NAP 2.0 represents the first update to the NAP software in several years. We've update the program to use the .NET framework, like our Reliability Workbench and Availability Workbench programs, which increases compatibility with modern Windows operating systems, and provides a more up-to-date user interface. It shares many new elements with our other applications, such as the Report Designer and Library facilities. Now, any NAP project can be opened as a library to facilitate sharing information between project files. Libraries also allow you to create common network elements and drag and drop them into your block diagram as needed.

Additionally, NAP 2.0 is in the first line of 64-bit applications we've ever released. You may have heard mention of 32-bit vs. 64-bit apps, or seen it in the context of Windows, e.g. Windows 7 32-bit version vs Windows 7 64-bit version, but not necessarily understood what exactly that means. It might sound a little bit like the computer nerd version of two car guys out-doing each other about the engine displacement of their muscle cars. "My '67 Camaro has a 283 cubic inch small block V8." "Oh, yeah? Well my '69 Challenger has a 426 Hemi!"
Basically, it refers to the amount of memory that can be accessed by the program or operating system. As an analogy, imagine a city planner designing a road and assigning addresses to the houses on the road. If he uses three-digit addresses for the houses, then the street could be a maximum of ten blocks long. However, if he uses four-digits, then he could have 100 blocks on a single street. Three digits may be all he needs for now, but if there are plans to further develop the neighborhood in the future, he might want to use four digits for the addresses.
Computer memory works similarly: the number of bits for the operating system or the application refers to the number of blocks of memory that can be addressed and used. The maximum amount of memory you can address with 32 binary digits is about 4 gigabytes. Back in the mid-90s when the first 32-bit processors and applications were developed, that was an obscene amount of memory. However, the future has come and gone and now we can max out a computer with 32 gigabytes of memory for a little over $200. 32 bits is simply not enough to address all that memory, so about a decade ago, computer hardware and software began transitioning to 64 bit addressing. The maximum theoretical amount of memory you can address with 64 bits would be 16 exabytes (or about 16.8 million terabytes), although practical limitations with the hardware make it a lot lower. In other words, we don't have to worry about maxing that out anytime soon.
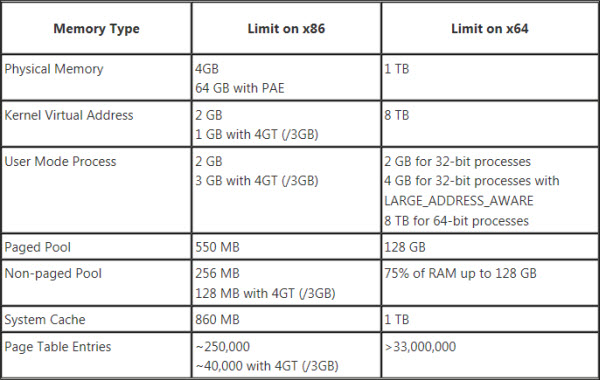
Even if you were using a 64-bit version of Windows, a 32-bit app could only use a limited amount of memory. After the operating system takes its cut, the app is left with about two GB to work with. Most of the time, that's fine. If you're building a small- to medium-sized fault tree, that's more than enough. But NAP's undirected connections and sockets make path generation a complex affair, and the number of cut sets can increase exponentially with regard to the number of paths. More than any of our programs, NAP users were crashing into the limits of 32-bit computing, so this program will benefit most from the 64-bit version.
While the latest release of Reliability Workbench (12.1) comes in both 32- and 64-bit flavors, NAP 2.0 is only available as a 64-bit app. So knock yourself out and build the most complex network model you can think of. The only limitation is the hardware constraints of your computer!
NAP 2.0 is available as a free upgrade to users with a NAP license and current maintenance. Contact Isograph today to download or to renew your maintenance.